Dave Irvine returns with his series on Access development. In this article, David steps back to discuss some of the underlying concepts of database design. David applies a system analyst’s approach to data design that you might find more useful than some of the more abstract methodologies currently in use.
Thinking back on my college days, I remember when my first course on database theory used a text that began, “To define a database, we must first define reality.” I almost blew that course! However, there’s some truth to the statement. Databases are collections of information used to solve real problems, and are models of real items and objects. Data is used to describe the world around us. A company has employees; the database has an employee table. Employee Dave Irvine gets a raise (I like that!); the salaries table is adjusted to reflect that raise. To understand what a database is, and how to use it as a tool to solve real-life problems, you must first understand what the problem is and the environment, or the world, that the problem lives in.
Relational databases in a nutshell
Microsoft Access has been touted as one of the best (or at least, one of the most widely used) relational database packages in the world. Many people think that the name “relational” is derived from the fact that the database allows you to join, or relate, one group of data to another. This is a perfectly fine definition for our purposes, but it isn’t the reason behind the name. The Relational Database Model is the result of the work of Dr. E. F. Codd (rhymes with God) at IBM. In 1970, Dr. Codd published a design for a database structure where the data was stored in a series of tables, or “relations.” A relation was a random collection of like data, where any one instance of all of the separate data items was unique. (Note: For an exceptional description of relational databases, see Access 2000 Developers Handbook, Volume 1, pages 94 – 121, by Ken Getz, Paul Litwin, and Mike Gilbert—Sybex, Alameda, CA, 1999.)
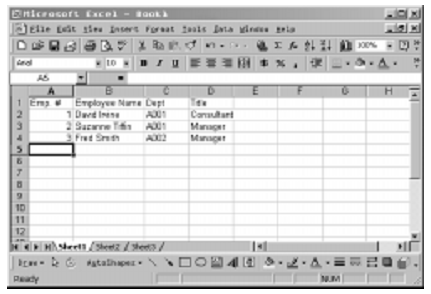
In a relational database, data is stored in tables (files, for us old structured hacks, tuples in Codd’s definition). Each table consists of columns of like data (fields, or elements) and a related collection of column items is a row (record or segment). If you think of another Microsoft product, Excel, then this definition becomes clear. A datasheet can be considered a file—that is, a collection of data organized into columns and rows. Consider the example shown in Figure 1.
Figure 1
This is an example of a Microsoft Excel worksheet, but it could just as easily be a relation or table. It’s composed of data, organized in like columns with a single item in each column, and all of the items forming a row. A query to retrieve all Employee Names would return David Irvine, Suzanne Tiffin, and Fred Smith, while a query to retrieve Employee 1 would return 1, David Irvine, A001, and Consultant.
If this is a table, where are the legs?
Now, I know that there are some purists out there who will argue with me, but to my mind, there are basically three types of tables (and this is very much a systems analyst’s view): master tables, transaction tables, and lookup tables. Master tables contain data that’s primarily static, such as customer records or employee records. These tables change very little over time, although they do require update methods, since customers come and go, or change their residences, and employees are hired, leave, and get promoted.
Transaction tables, on the other hand, are extremely dynamic, in that the data in them is added to or changed on a regular basis. Customers place orders, which must be filled, shipped, invoiced, paid, deleted, back ordered, and so forth. Transaction tables, as the name implies, hold the day-to-day transactions that reflect the course of doing business.
Lookup tables are extremely static tables, which change very little. These tables generally contain very few elements (columns) per segment (row) and are used to supply and verify information used in other tables. One example might be a department table, which contains the department code and department name for all departments in an organization. This table might be used in an employee maintenance form. The user inputs a department code, and the system looks up this code in the department table to verify that it’s valid. Alternatively, the form might contain a pull-down list with the names of the departments in it, and the user selects the appropriate value. In these ways, the programmer can ensure that the user can enter only valid departments, thus improving the reliability and the integrity of the system.
All three of these kinds of tables see changes, but the rate of change is sharply different between them. Lookup tables hardly ever change, master tables change more frequently, and transaction tables change constantly.
One key element of the Relational Model, as defined by Codd, is that the data in each table must have unique rows. This fulfills two goals. First, it frees the data from the storage media (you don’t have to know where the record is on the disk to access it). Second, the data has no set access path or structure, unlike the sequential file method of early data processing systems. To establish the uniqueness of rows in a table, you must establish a primary key, or index. The primary key is a data item in the table that never repeats across the rows of a table. A lookup on the primary key item returns, at most, only one row.
A primary key can be a single field or a combination of fields, which is called a compound key. The decision as to which field(s) to use as a primary key is left up to you, the database developer. When choosing a primary key, try to keep it simple. Use as few database columns as possible, and try to pick data that’s static, and won’t change, or at least not change very much or very often (see the sidebar “Death on the Highway: Surrogate and Primary Keys” for what can go wrong if you don’t use primary keys correctly).
As well as a primary key, which is always unique, a table might contain secondary keys. Secondary keys are fields that the designer or the user might want to use to look up or group information, and which might repeat. An example might be the City field in a Customer table. You might want to extract just the customers that are located in a single city, or you might want to produce a customer list, sorted and broken by city. These types of actions are facilitated by the use of a secondary key. Where a secondary key duplicates a primary key in another table, it’s called a foreign key. Foreign keys are typically used to join one table to another.
What’s a nice person like you doing in a join like this?
As I mentioned in the beginning of this article, the definition of relational database as the ability to relate one table to another isn’t quite accurate, but it will do fine for our discussion. One of the great strengths of Access, or any other relational database, is the ability to relate one data table to another. These relations, or joins, allow you to connect separate but related pieces of data, and let you perform more complex data manipulation. Figure 2 shows a simple two-table relationship.
In the example in Figure 2, I have two simple tables: the Department Table and the Employee Table. The Department Table is a lookup table, containing the Department Number, which is its primary key, and the Department Name. The Employee table contains the Employee Number, Employee First Name, Employee Last Name, and a number of other employee-related data fields, including the Employee Department Code. The Employee Table is indexed on the Employee Number, which is the primary key, and the Department Code, which is the foreign key that facilitates the join to the Department Table. The index on Department Code also supports sorting the table by department, selecting employees by department, or producing reports that group employees by department.
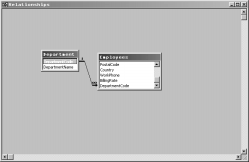
Figure 2
The type of join illustrated in Figure 2 is known as a “one-to-many” relationship. This means that any one Department can contain many Employees. If the relation is considered in reverse, from Employee back to Department, then it’s a “many-to-one” relationship, where many Employees have the same occurrence of Department.
A relationship can also be “one-to-one,” where a single entry in one table relates to one, and only one, entry in the joined table. This is created by linking tables via common, non-duplicating keys—typically the primary key. Since the primary key can’t be duplicated, any one record in table A will match one, and only one, record in table B. An example of this might be a table containing hospital patient information, and a table containing related, but separate, confidential patient information. In this case, every patient would link to one, and only one, confidential record, and every confidential record relates to one, and only one, patient record. A patient database might be constructed in this manner for security reasons, allowing a general user to access the patient table but only authorized users to access the confidential table.
The relational model excludes the existence of a “many-to-many” relationship between one table and another. Since tables are joined by way of a Primary Key, it’s impossible for a key entry in one table to link to multiple key entries in another table. This kind of join can be simulated, however, by using an intermediary or link table, as shown in Figure 3.
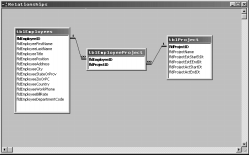
Figure 3
In this example, I’ve used an intermediary table tblEmployeeProject to link from Employees to Projects. The primary key in the intermediate table is a compound key, made up of the fldEmployeeID and fldProjectID. This means that the combination of the two fields is unique, such that a given employee can’t be working on a specific project more than once. An employee can be working on several projects at once, and every project might have several employees. By using the intermediary table, I’ve satisfied the many-to-many (M’M) relationship.
In terms of my distinction between master, transaction, and lookup tables, one-to-many relationships typically exist between lookup tables and the master or transaction tables. It’s this relationship that Access takes advantage of in the Lookup tab of the Access table designer. This tab lets you specify for a foreign key field what data to retrieve from the primary key table. Many-to-many relationships, on the other hand, typically occur between master tables where the intermediary table acts as a “lookup to a lookup” table. These relationships are less useful in the Access Lookup tab. One-to-one relationships also typically occur only between master tables and can be useful when working with the Lookup tab.
Normalizing
In 1972, Dr. Codd introduced the concept of Data Normalization to the Relational Database Model. In a nutshell, normalization is the process of making the database more flexible by eliminating redundancy and inconsistent dependencies. The purpose of this is to save disk space (by not storing redundant, or repeated data) and to ease maintenance. Without normalization, the same data can exist in multiple tables, and, when that data changes, the change must be done to all of the tables in which the data exists. In addition to reducing the storage required for your data, normalization also reduces the number of tables that must be updated when data changes.
“Inconsistent dependency” is the idea that data should be dependent on a logical structure. It makes reasonable sense to look in the Project Table to find the actual start date of a project, but it makes much less sense to look there for the phone number of a customer.
There are several levels of database normalization, and each level is referred to as a “normal form.” There are a few more levels, but for all practical purposes, the third normal form is the highest level required for most applications (for a thorough discussion of normal forms, see Peter Vogel’s two articles “The Trouble with Normal” and “Getting Normal” in the January and February 1998 issues of Smart Access, respectively).
This is in no way an exhaustive study of Access database design—several excellent references exist on the subject. I wanted to provide an overview of some of the fundamental relational databases design issues before going on to the next topic in this series. In future issues, for instance, you’ll see these concepts cropping up in discussions on how to use queries and building complex forms and reports.
Sidebar: Death on the Highway: Surrogate and Primary Keys
Some designers, in order to improve performance, use an arbitrary number as the surrogate key. These designers first determine which data item is the primary key for the database and then build a unique index on it. They then go on to take advantage of Access’s ability to create autonumber fields, and use this feature to generate another unique key—the surrogate key. While the data item key might be a compound key or consist of string data, the surrogate key will be single numeric field. Single numeric fields give you the best performance in lookups and table joins in most DBMSs. It’s important to recognize that it’s still essential to determine which data items make your rows unique. Bad things happen to good tables when an autonumber field is the primary key instead of being a surrogate for the primary key.
For instance, Doug Den Hoed reports that he was brought in by one of his Oracle clients to solve a problem with a database created by another developer. The client was having his Oracle data slowly corrupted by an Access application (though the problem could just as easily have occurred in SQL Server or any other remote DBMS). Doug’s client had a data design consisting of tables with no primary key other than a single autonumber-type field. This created a problem when records were added to the database. Since the autonumber field isn’t generated until a record is actually inserted into a table, Access couldn’t use the primary key field to identify the record for further processing. The result was that Access would insert one record but then make some other record in the table the current record for processing. The client sometimes ended up editing a different record than the one that had just been added.
Mike Gunderloy described what was happening under the hood: “If you watch Access working via SQL Profiler, you’ll see that after an insert in a table that uses an autonumber-type field for the primary key, Access will issue a find with a WHERE clause consisting of all of the entered values in the record to find the record after it’s been inserted. “When Access used the current values of the fields in the record in an attempt to identify the row, Access sometimes retrieved a record other than the one that had just been added. This was because the data design allowed multiple rows to be identical except for the primary autonumber field. Mike summed up the problem as being in the design, not the tool: “Personally, I would blame whoever designed a database where the only difference between two rows in the same table is a synthetic key. That’s not a normalized design.”
Doug wasn’t in a position to redesign the client’s database, but he was able to put in a workaround that reduced the scope of the problem: “In the BeforeInsert event of the form, I now run a passthrough query and grab the NEXTVAL from the sequence, then punch it into the underlying ID field on the form’s Recordset. Since the trigger only fires to get the sequence when the new.ID is null, I’ve essentially beaten the trigger to the key. More importantly, since Access now knows about the ID value at BeforeInsert time, and because that ID doesn’t change anymore, Access can keep track of the record. So as long as the users enter new rows using the form, I’ve worked around the problem.” As Doug goes on to point out, though, the solution has a cost—an additional access to the database. Getting the data design right in the first place would have given Doug’s client a faster application. In addition, the client is still facing the problem of tracking down and cleaning up all of the bad data that now exists in the database’s tables.
