In this column, Peter takes on a research study database. In addition to showing how you can apply your skill with SQL to solve a problem that might have required several hours of VBA code, Peter also demonstrates some SQL tricks of the trade.
When I first started this Working SQL series back in 1996, I said that my hope was to provide you with some insight into the way that SQL works. It’s probably become obvious that I had a hidden agenda: I think that we write too much code and not enough SQL. I wanted these articles to give you the tools that would let you use SQL more.
Some of the people who’ve written me about these articles have been kind enough to say that they’re using SQL more in their applications. However, the one thing that I’ve noticed is that the developers I meet generally don’t need to learn more about SQL. Between what they already know and the Access Query Design window, they can generate pretty much all the SQL they need.
What I have discovered is that developers often don’t recognize when they can apply SQL. I see a lot of developers using recordset DAO methods like Seek or Find instead of SQL. In this month’s issue and the next, I’d like to take two examples from my own experience to show how SQL can be used. You can follow along with this month’s case study in the Access 2.0 database in the accompanying Download file.
A research case
I received this case from Jerry Schulman, who runs Total Command! Database Design in Ontario, Canada. (Here’s Jerry’s description.)
“I’m building a database for a research lab at a local hospital. The work of the lab involves studying diseases that might have a genetic component — that is, they run in families. The database includes a bunch of tables for managing tests and samples, but the ones that I’m concerned with now hold patient and family information.
“Families are recruited into the study from various hospitals around the country. Each family has a contact person, called the proband, who has the disease. Each person, whether diseased or a relative of the diseased person, is identified in the PatientInfo table by a FamilyId and MemberId number. These people might have a diagnosis, indicating that they also have a disease. You can see the structure of the family and patient information tables in Table 1 and Table 2.
Table 1. The original FamilyInfo table.
| Field name | Field type and length | Primary key? |
| FamlyId | Text-25 | Yes |
| Source | Text-50 | No |
| Proband | Text-25 | No |
Table 2. The PatientInfo table.
| Field names | Field type and length | Primary key? |
| FamilyId | Text-25 | Yes |
| MemberId | Text-25 | Yes |
| Diagnosis | Text-250 | No |
| Study | Text-12 | No |
| Relation to Proband | Text-10 | No |
| DateOfBirth | Date/Time | No |
“So, here’s the problem: how to assign a group ID to families based on characteristics of the families’ individual members. For example, families can be composed of affected people who have different cancers. As well, a family can have siblings who are affected (intragenerational), or parents and children who are affected (intergenerational). Some families are also included in which only one member is affected (neither inter- nor intragenerational). If a family has both inter- and intragenerational diseases, then the family is classified as inter.
“I want to be able to identify families with intergenerational diseases of a single type, and families composed of both inter- and intragenerational diseases of several types. Still other groups of families have only one affected member. As you can see, there are many possible family types when one looks at inter- vs. intragenerational disease and whether a single cancer type or multiple cancer types are present.
“I’d like to be able to group families in queries or reports on the basis of disease and study. It’s important that this be done dynamically, as over time new members might develop a disease or have their diagnosis changed.”
A SQL solution
The first thing that Jerry and I recognized was that the data was being categorized in two different ways: the number of different types of cancer and the type of incidence (inter- or intragenerational).
The first step in the SQL solution, therefore, involves adding two fields to the FamilyInfo table as shown in Table 3 — one field called IncidenceType and another called IncidenceCount. One of the central tenets of database applications is that all of the information about the problem has to be stored in the tables. If you want to use SQL to manage your data, then you’re not allowed to store “facts” about the data in VBA code that operates on the data. Among other things, putting all your data in tables makes it considerably easier to report on your data.
Table 3. The revised FamilyInfo table.
| Field name | Field type and length | Primary key? |
| FamlyId | Text-25 | Yes |
| Source | Text-50 | No |
| Proband | Text-25 | No |
| IncidenceCount | Single | No |
| IncidenceType | Text-5 | No |
With someplace to store the data, I could go on to fill those fields with the appropriate values. The first thing that I wanted to do was to count the number of different diseases in a family and use that to update the IncidenceCount field. Getting that count turned out to be a bit of a problem.
The PatientInfo table had both family and diagnosis information, but a query on the PatientInfo table can’t count the number of diseases in a family. This query (qryCountFamilyRecords), for instance, counts the number of records for each family:
Select FamilyId, Count(Diagnosis) From PatientInfo Group By FamilyId
However, the result of that query doesn’t tell you whether the family has several different diseases or just one disease several times. In fact, it doesn’t even give you a count of just the patients with a disease. To eliminate those patients with a clean bill of health, I’d have to add a Where clause that filters out all the patients with a diagnosis (qryCountFamilyWithDiagnosisRecords):
Select FamilyId, Count(Diagnosis) From PatientInfo Where Diagnosis > " " Group By FamilyId
Check out the sidebar “Where vs. Having” for a discussion of the role of the Where clause in Total queries.
What I needed was a table that listed each family once for each different diagnosis in the family. The following query, based on the PatientInfo table, does just that. It finds all of the Family and Diagnosis combinations and uses the Distinct operator to eliminate duplicate rows. It also uses a Where clause on the diagnosis field to select only those family members with a disease:
Select Distinct FamilyId, Diagnosis From PatientInfo Where Diagnosis > " "
I called this query qryCountDisease and stored it in the database. Since Access treats Select queries as if they were tables, this query effectively gave me the table that
I needed.
The next step was to create a query based on qryCountDisease that would count the number of records in qryCountDisease for a family. This query is a Totals query that groups on FamilyId and counts the number of diseases per FamilyId:
Select FamilyId, Count(Diagnosis) From qryCountDisease Group By FamilyId
I called this query qryCountIncidence, and its sample output can be seen in Table 4.
Table 4. Sample results from qryCountIncidence.
| FamilyId | CountOfDiagnosis |
| Jones | 1 |
| Smith | 4 |
| Doe | 2 |
It’s worthwhile to point out that this two-step query wouldn’t have been necessary if Access allowed you to specify the Distinct clause with the Count function. If Access did, I could have used a single query like this:
Select FamilyId, Count(Distinct Diagnosis) From PatientInfo Where Diagnosis > " " Group By FamilyId
While this statement is valid in the ANSI SQL standard, it’s not supported in Access SQL.
Now that I had a query that returned the number of diseases for each family, I could use it to set the IncidenceCount field. Ideally, this would only involve creating an update query that joins the FamilyInfo table to the qryCountIncidence query in order to set the IncidenceCount field to the value of CountOfDiagnosis:
Update FamilyInfo Inner Join qryCountIncidence On FamilyInfo.FamilyId = qryCountIncidence.FamilyId Set FamilyInfo.IncidenceCount = qryCountIncidence.CountOfDiagnosis
Unfortunately, Access rejects this query with the message “Operation must use an updateable query” (so I’ve called the query qryUpdateIncidenceCount-Fail in the sample database). The problem is probably that Access doesn’t realize that qryCountIncidence will only return a single record for each FamilyId. As a result, Access thinks that the join between FamilyInfo and qryCountIncidence is a one-to-many join and that I’m trying to update the “one” side of the join. This isn’t allowed (in fact, many databases won’t even allow you to update the “many” side).
The solution to this problem is trivial but annoying. I converted qryCountIncidence into a Make Table query that created a table called tblCountIncidence. This change is easy to do in the Access Query Design window, and the resulting SQL looks like this:
SELECT DISTINCTROW qryCountDisease.FamilyId, Count(qryCountDisease.Diagnosis) AS CountOfDiagnosis INTO tblCountIncidence FROM qryCountDisease GROUP BY qryCountDisease.FamilyId;
I then used the resulting table in the update query (qryUpdateIncidenceCount):
Update FamilyInfo Inner Join tblCountIncidence On FamilyInfo.FamilyId = tblCountIncidence.FamilyId Set FamilyInfo.IncidenceCount = tblCountIncidence.CountOfDiagnosis
Incidentals
Now I was ready to set the IncidenceType to “Non”, “Intra”, or “Inter”. There are probably three or four different ways of doing this, but I chose to use a method based on successive refinement. Basically, this meant that I began by setting everyone to a “Non” status (indicating only one member has a disease). Obviously, this is going to set a lot of records incorrectly. So, in the next step, I set every family that had diseased members who were brothers or sisters of the proband to “Intra” (indicating all diseases were among siblings). In the final step, I set the family records to “Inter” where some family member other than a brother or sister to the proband had a disease.
The query to set all the families to “Non” is the simplest (qryUpdateIncidenceTypeNon):
Update FamilyInfo Set IncidenceType = "Non"
With that done, I then set the type for all of the intragenerational (and, inadvertently, some of the intergenerational) families to “Intra”. I used a two-step query. In the first query, I found all of the families where a person with a disease was a sibling of the proband (qryIntraGenerational):
Select FamilyId From PatientInfo Where (RelationToProBand = "Brother" Or RelationToProBand = "Sister") And Diagnosis > " "
The second query in this step updates family info with the results of qryIntraGenerational. This query joins the FamilyInfo table with the families that appear in qryIntraGenerational and updates the IncidenceType field where there’s a match (qryUpdateIncidenceTypeIntra):
Update FamilyInfo Inner Join qryIntraGenerational On FamilyInfo.FamilyId = qryIntraGenerational.FamilyId Set IncidenceType = "Intra"
Fortunately, Access didn’t object to this query, and I wasn’t forced to create another work table. You might have noticed that this query sets a lot of the FamilyInfo records incorrectly. After all, even though a brother or sister is infected, there might also be an uncle or aunt or parent who’s also infected. Some of the records I’d just flagged as intragenerational were really intergenerational families. I fixed that in the next, and final, query of the series.
In the final step, I set all the intergenerational families to “Inter”. Not surprisingly, this step also consists of a query that extracts the correct records and then uses them to update the FamilyInfo table. The query that extracts the records uses a Where clause that finds all records where a person with a disease is not a brother or sister of the proband and so not a sibling (qryInterGenerational):
Select FamilyId From PatientInfo Where (RelationToProBand <> "Brother" and RelationToProBand <> "Sister") And Diagnosis > " "
And, as before, the second step is to create a query that updates the IncidenceType with “Inter” by joining FamilyInfo with qryInterGenerational:
Update FamilyInfo Inner Join qryInterGenerational On FamilyInfo.FamilyId = qryInterGenerational.FamilyId Set IncidenceType = "Inter"
So, by creating seven queries and running five of them (which, in turn, run the other two), all of the families are categorized as to the number of different diseases and their type.
Staying up to date
Of course, these settings will go out of date as new data is added or existing records are changed. In theory, these queries should be rerun after every change in the database. However, a schedule that reran them daily (or even just before reports are run) would probably be sufficient. The rerun schedule will be determined, at least in part, by how long the queries take to run. The runtime of the queries will be dependent on a number of variables: how much data there is in the database, the speed of the computer, the number of indexes on the tables, and so forth. Given the number of variables, I can’t provide runtimes for this process. The queries would take so little time to construct, though, that the best answer would probably be to go ahead and create the queries, and then run them with a stopwatch handy. It only took me about an hour to pull this solution together, for instance.
If the reruns take too long or letting the data go out of date between runs isn’t acceptable, then a slightly different approach needs to be taken. An alternative strategy is to create queries for reporting on the tables and use VBA functions in those queries to generate the equivalent of the CountIncidence and IncidenceType fields. A typical query might look like this (qryVirtualTypeCount):
Select FamilyId, CountIncidence(FamilyId) as IncidenceCount, TypeIncidence(FamilyId) as IncidenceType From FamilyInfo
See the sidebar “VBA Functions in a Client/Server Environment” for a warning on using this method.
So what do these functions look like? One solution begins by storing a query that uses qryCountDisease in the database as a parameterized query (I called the query qryVirtualCountIncidence):
Parameters FamilyParm Text; Select CountOfDiagnosis From FamilyInfo Inner Join qryCountIncidence On FamilyInfo.FamilyId = qryCountIncidence.FamilyId Where FamilyId = FamilyParm
The function that uses that query to return the CountOfDiagnosis looks like this:
Function CountIncidence (FamilyId As String)
Dim dbs As Database
Dim que As QueryDef
Dim rec As Recordset
Set dbs = CurrentDB()
Set que = dbs.QueryDefs("qryCountIncidence")
que.Parameters("FamilyParm") = FamilyId
Set rec = que.OpenRecordset()
If rec.Recordcount = 0 Then
CountIncidence = 0
Else
CountIncidence = rec("CountOfDiagnosis")
End If
rec.Close
dbs.Close
Set rec = Nothing
Set dbs = Nothing
End Function
The TypeIncidence function is slightly more complicated. Here, I reversed the refinement process I used before and first checked to see whether the family was intergenerational before checking to see if it was intragenerational. In both cases, I attempted to retrieve the records that would indicate whether the family was inter- or intragenerational. If any records were found, I knew the type of the family. While it’s almost always more efficient to store parameterized queries in the database than to build them on the fly as I do here, I wanted to show an alternative solution to the previous function. To make this code more readable, I’ve also used the VBA line extension character, which isn’t available in Access 2.0:
Public Function TypeIncidence (FamilyId as String)
Dim dbs As Database
Dim rec As Recordset
Set dbs = CurrentDB()
Set rec = dbs.OpenRecordset("Select FamilyId " & _
"From PatientInfo " & _
"Where (RelationToProBand <> 'Brother' " & _
"And RelationToProBand <> 'Sister') " & _
"And Diagnosis > ' '" & _
"And FamilyId = '" & FamilyId & "';")
If rec.RecordCOunt > 0 Then
TypeIncidence = "Inter"
Else
Set rec = dbs.OpenRecordset("Select FamilyId " & _
"From PatientInfo " & _
"Where (RelationToProBand = 'Brother' " & _
"Or RelationToProBand = 'Sister') " & _
"And Diagnosis > ' '" & _
"And FamilyId = '" & FamilyId & "';")
If rec.RecordCOunt > 0 Then
TypeIncidence = "Intra"
Else
TypeIncidence = "Non"
End If
EndIf
rec.Close
dbs.Close
Set rec = Nothing
Set dbs = Nothing
End Function
The importance of SQL
So here are two solutions that use no recordset methods or properties (except for RecordCount). You should find the technique of generating a query of records and then using that query to update a table useful in a variety of situations.
While working on this article, it occurred to me that, while I’m stressing the importance of SQL, what’s really important here is the research that these queries support. I’ve lost family members to cancer and, as a result, got some satisfaction from participating (in a very small way) in this effort. And, by using SQL, I think I also contributed the best possible solution for this part of the problem.
Sidebar: Where vs. Having
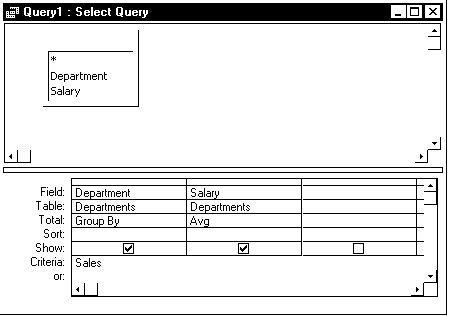
In creating Total queries, you want to distinguish between using Having and Where. The Having clause extracts records that meet criteria after the totaling has been done. For instance, this query reports the average salary for the Sales department. It does this, unfortunately, by using the Having clause, which generates the average salary for all the departments and then displays only the record for the Sales department:
SELECT Departments.Department, Avg(Departments.Salary) AS AvgOfSalary FROM Departments GROUP BY Departments.Department HAVING (((Departments.Department)="Sales"));
The Where clause, on the other hand, extracts the records before the totaling is done. As a result, only the records that are needed by the query are totaled. Here’s the same query, only considerably more efficient:
SELECT Departments.Department, Avg(Departments.Salary) AS AvgOfSalary FROM Departments Where Departments.Department="Sales" GROUP BY Departments.Department
As Figure 1 shows, the Access Query design window makes it very easy for naive users to use Having when they wanted to use Where. Figure 1 shows the inefficient version of this query. The efficient version of the query is shown in Figure 2.
Figure 1
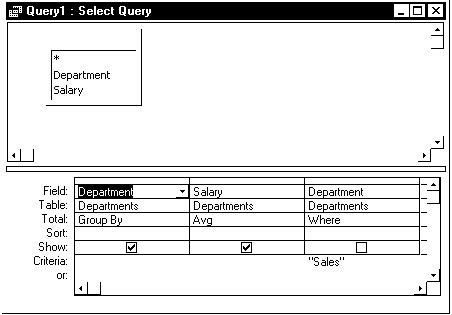
Figure 2
Sidebar: VBA Functions in a Client/Server Environment
If you use a database server like Oracle, SQL Server, or Informix, you have to be careful when using VBA functions (built-in or user-defined) in your queries. The important thing to remember is that your database server doesn’t support VBA. As a result, any processing done by VBA must be done on the computer that issued the SQL statement. In this example, that’s not really a problem:
Select FamilyId, CountIncidence(FamilyId) as IncidenceCount, TypeIncidence(FamilyId) as IncidenceType From FamilyInfo
Here, the FamilyId will be returned to the client computer, and the VBA functions CountIncidence and TypeIncidence will be processed (this might involve additional calls to the server).
This query, on the other hand, does have a problem:
Select FamilyId, CountIncidence(FamilyId) as IncidenceCount, TypeIncidence (FamilyId) as IncidenceType From FamilyInfo Where CountIncidence(FamilyId) > 2
In this situation, the test on CountIncidence(FamilyId) can’t be done until the VBA processing is done. As a result, all of the records must be fetched from the server for processing before any of the records can be rejected by the Where clause. Not very efficient, but it’s hard to imagine what else you could do without storing the data in the FamilyInfo table.
