Thorough, thoughtful, and accurate data modeling should be the starting point of detailed database design. But a surprising number of developers have little or no understanding of data modeling and shy away from what sounds like a non-profitable and time-consuming task. Glenn Lloyd looks at the typical design pitfalls that trap Access beginners and shows the basic techniques that ensure success.
My call came from a community service organization that provides specialized services both locally and remotely across the vast expanse of Northern Ontario. They were unable to solve a problem with their Access database – a problem that was both embarrassing and damaging to their relations with their membership (and to the community at large). Several months earlier, one of their key members had died. Now, despite their best efforts, his widow and the other organizations with which he had been associated were still receiving their periodic mailings addressed to him. As I listened to the story, I realized that the problem indicated a faulty database design. The staff that had developed the database had no training or understanding of relational design principles and rationale. What they had known was how they wanted to see their data laid out in reports and had designed a data structure that matched those report layouts.
What made the problem embarrassing was who had died. The organization’s membership is derived from local community organizations located in various centers across Northern Ontario. Board members can represent one or more of these community organizations. The member whose death triggered the problem was a prominent member of one of the communities and either officially or unofficially represented a number of the constituent organizations. This was a very visible mistake.
The original sin
One of the goals of the original database was to have targeted mailing lists so that mailings could be restricted to specific individuals or groups according to the purpose of the mailing. The original database designers concluded that they could best accomplish this objective by subdividing membership data into several tables, one for each of the eight or nine categories that best described the community organizations the members served. This meant that some individuals, including the recently deceased member, had multiple entries, one in each of the relevant membership tables. The member whose information had brought the problem to light had at least four or five of these entries.
When all is said and done, a database is nothing more or less than a model of the real world. So, before an efficient relational database can be designed and implemented, the developer or developers must have an in-depth understanding of the nature of the real world that the database will model. A membership database, for example, doesn’t contain real people. A database contains information that may be about real people. That information describes who the real people are, where they live, the membership category to which they belong, special skill sets they bring to the group, and any other information the owners of the database need to retain about their members.
“Data modeling” refers to the first step of detailed database design. Data modeling is the basis of the ultimate table and relationship design that, when implemented, becomes the database’s structure. Data modeling’s purpose is to translate the real-world requirements (described either formally or informally) into a formal data structure.
The process of data modeling is as vital to database design and implementation as the structure that’s produced because the process requires you to study the organization and the information you want the database to track. As a result, when you follow the process you come to know your data very well and move from mere assumption and speculation to in-depth knowledge of the organization and its information needs. Along the way, you define your database structure.
While you may have already worked out an intuitive solution to the problem, don’t pat yourself on the back. Without a process, you can’t guarantee that you would have spotted the problem before it became a problem. And you don’t know that you’ll do as well with every other problem that you face. Data modeling can be done a number of different ways, but I’ll walk you through a simple three-step data modeling process. By the end of this article you’ll see how this process would have led, inevitably, to a practical solution to my client’s problem.
Step 1: Make a list
In this first step, it’s best to step back from any thoughts about how you’ll eventually organize the data. Your first step is do a simple “brain dump” of everything the database is required to track. A formal or informal requirements analysis is the best guide for this step.
For example, assume that the database in question is a membership database. The company requesting the database (client, boss, or whoever has determined that the database should be developed) has set out several basic pieces of information they want to know about members. Name and address are obvious, of course. In addition, however, they also want to have some indication of special skills or capabilities the member has to offer the organization, whether the member is a director or executive board member, and the organization or organizations that the member represents along with the category to which the external organization belongs.
Step 2: Separate subjects and descriptions
The database requirements analysis provides only a guide of “what” the database is required to track. Those items aren’t all of the same kind:
- Some of the items in the list are distinct types of subjects for the database.
- Others describe or classify the subjects.
Typically, your initial brain dump will generate a similar mixture of subjects and descriptions. The goal of the second step is to clearly identify and separate subjects from their descriptions.
The technical RDBMS name for the subjects is “entity.” Of course, the database would be a rather limited tool if all it maintained was a list of entities. In fact, the real purpose of the database is to organize and store bits and pieces of descriptive information (called “attributes”) about the database’s entities. Entities correspond to tables in the ultimate database; attributes correspond to the tables’ fields. Category or classification information presents a special case because categories themselves are entities whose members describe other entities.
Two basic questions guide your work in this step: Which of the list items are entities and which are attributes (information about a particular entity)?
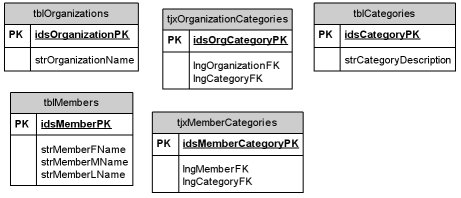
For example, if “members” are one of the subjects of a database (an entity), information describing members might include name, birth date, gender, physical stature, and member or account number (attributes). Each of these attributes speaks directly to who the real member is. By taking the analysis to this level, you now have a model of how you’ll represent a member in the database and can translate the description into the definition of a table of members. The translation is quite straightforward. The entity (or “thing”) becomes a table; each attribute becomes a field in the table.
The resulting table is shown in Figure 1 and incorporates two design standards that I apply to all my databases. First, each table should have a single field, not part of the data, that identifies the record. This becomes the table’s primary key. Second, each attribute should be indivisible: I should never need, in any application, to pull out data “inside” the attribute. As you can see in Figure 1, I broke the name down into three component attributes: first name, middle name, and last name.
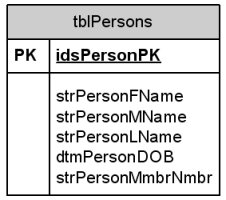
Figure 1
Finding entities
Does this table satisfy all of the information needs about the people in the database? Most certainly not! What it does satisfy is the need for information that directly describes each person to the degree that the client and developer have agreed that the person needs to be described for this organization and database. In the list of “what to track,” in my membership database, members and organizations are quite clearly distinct entities. A member isn’t an organization and an organization isn’t a member.
Not all decisions are so straightforward. For instance, is an address an entity or an attribute?
From the data modeling perspective, the answer depends on whether organizations and/or members represented in the database happen to share addresses. In my case, organizations and persons could share addresses. If an organization and a person can share an address, then it suggests that the address is a separate entity with an existence of its own that’s independent of the organization or person it belongs to. Therefore, addresses are entities and will have a table of their own.
After the obvious physical subjects come the more conceptual subjects that you may need to track. Depending on the organization’s business rules, you may need additional entities to track relationships between subjects. For instance, because addresses are an entity in my database, I need an entity to track the relationship between addresses and persons or organizations (or both). In my database, I’ll have an Organization/Address table to track the relationship between organizations and addresses.
Categories form another problem. For instance, a person can be a president, board member, or have some other role in the organization. Don’t those categories describe the person and, therefore, shouldn’t they be represented by additional fields in the person table? The simple answer is no. A category doesn’t describe the subject to which the category applies. A category describes how a subject relates to or interacts with other subjects and with the overall organization. A category doesn’t describe a subject in isolation from other subjects. A category does have a relationship with a subject, however, and the relationship does require an entity.
For instance, look at the category “organization type.” Rather than being an attribute of the organization subject, the organization type describes a relationship among organizations: Types only make sense if several different entities share the same type. Since an organization has a relationship with the organization type (an organization belongs to a type), you need an entity to track relationships between organizations and their types: an Organization/Category table.
The same kind of analysis applies to a person’s role within an organization: directors, officers, and executives. Each of these terms describes a particular role a member might have in an organization. In other words, they’re a category that describes the relationship between an organization and a member: You can’t be a president unless you have an organization to be president of. So I need a Membership/Role table to track the relationship between a member and a role.
While I could have had separate tables for MemberCategory and OrganizationCategory, I chose not to. As Figure 2 shows, the categories for organization and members share a common Categories table with tables that describe the MemberCategory/Member and Organization/OrganizationCategory. The rules that drive this decision are worth explaining. However, you’ll have to come back next month for that.
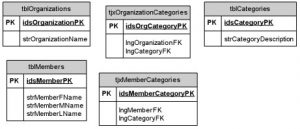
Figure 2
