In part 1, Glenn Lloyd started outlining his approach to data modeling. This month, he finishes his discussion of the rules that ensure that your database will actually work after you’ve built it.
Last month I had developed a data model based on one of my client’s needs. The point of the article wasn’t to show off that particular database but, instead, to show how to start with your users’ requirements and end up with a data model. The next step is to go from the data model to an actual database.
Before I begin, however, I want to emphasize that good data modeling isn’t a “nice-to-have feature.” It’s essential to success. I had one client who managed a sales route business that included 30 trucks supplying customers over a wide sales territory. I’d met the client when he attended one of my Excel training classes. Several months later, I happened to be talking with him when he proceeded to describe the complex multi-sheet Excel solution he had developed to manage his route salespeople and distributed inventory. The flat file approach he used, of course, had an almost unlimited potential for costly errors because of data redundancy and undetected formula errors. I didn’t have the heart to tell him that this “first-born” of which he was so proud would almost certainly grow into an unmanageable and useless monster.
A second client, a small industrial products manufacturer, also had implemented an Excel solution for inventory management. The person I dealt with had inherited the workbook, which consisted of some 60 worksheets. He called on me to help him gain some confidence that different parts of the workbook were being properly updated when other, related, parts changed. Specifically, he needed to be able to calculate and apply pricing changes across a wide variety of products. Many of the products in this case were assemblies of various combinations of components the company manufactured. Once again, this was a flat file solution with a virtually unlimited potential for costly errors. Given that many of the products the company manufactured had four-, five-, and six-digit prices, the worksheet solution posed a serious and needless risk of potentially costly data errors.
The two rules
Two fundamental rules underlie the process of moving from the data model to the actual data tables. They may be so obvious that you just take them for granted, but it’s worth stating them explicitly:
- Rule 1: Each entity should be represented by its own table.
- Rule 2: Every instance of an entity should be stored in the same table.
I recently had to review and modify another client’s database where the initial designer had little or no understanding of these rules. In their design, each company my client did business with had its own table (and all of the tables looked very much alike). With this one decision, my client managed to violate both Rule 1 and Rule 2.
It got worse: Some of my client’s customers had multiple divisions and branches. Each time my client did business with a different part of a company or there was a change of contact person for the company, my client added a new record to that company’s table. As a result, each table had many records. These tables weren’t really company tables (because a single company appeared many times in the table), nor were they division/branch tables (because the differences in the records were also driven by changes in contact names).
While the database had been intended as a tool to improve marketing efficiency, it had turned into a millstone, seriously hampering the client’s marketing efforts. There were also several spelling and name variations for some companies but, since each company had multiple records (and each had its own table), it was difficult to track down the errors. Determining which customers to include in periodic promotional mailings and making sure the correct information was used had become increasingly labor-intensive. It had come to the point that the business was on the verge of financial failure. Lack of ability to maintain current market information was crippling the company and its ability to remain competitive in a specialized marketplace.
Rule 2 speaks directly to the issues outlined in the community service organization story I described last month. The client had created separate tables; they intended each table to deal with one particular category/member combination. The rationale was that they needed to be able to distinguish between the types of representatives that comprised their membership. They didn’t want to mingle political representatives, community service organization representatives, and aboriginal representatives, for example, in the same list.
The point they overlooked was that, regardless of the group or organization the member represented, all of these representatives were members. Reduced to their lowest common denominator, they all were part of the same entity and therefore belonged in the same table. Artificially separating them into different tables led to redundant data and those unfortunate duplicate mailings.
Separating categories or any other entities into multiple tables presents another problem that’s seldom apparent to the uninitiated: What happens when you decide you need another instance of the entity? Logically, if you have multiple company tables, you should “simply” add another table for the new company. That sounds easy enough. However, the new table will require a whole new set of queries and reports. Most likely, a number of existing queries and reports will also have to be modified to accommodate the additional company. Compare the effort involved to do all of that to the minimal time and effort it would take to add a new company record to the existing single table of companies.
The importance of questions
Properly applied, the first two steps offer two benefits. Not only do you get a solid design for the tables in your database, but you also enhance your understanding of the data that you’re working with. Frequently, working through the data model will bring to light new questions. Determining the answers to those questions in the final steps of modeling will give you invaluable insight into how the various entities and your database tables fit together and relate to each other. The questions that are raised, and your ability to raise them with the client during the database development, will often prove to be one of your most valuable development resources. The process is as important as the result.
Recently, a client hired me to develop a custom Access reporting package. Several years old, the existing database couldn’t accommodate some of the client’s key reporting requirements. In a situation like this, it’s always easy to second-guess the original developer. After all, how could they anticipate in 1999 the reports and data that the client might need in 2005? However, it soon became apparent that at least some of the information the client now wanted to report on had been anticipated to a certain extent. The database included a table of customers who were assigned funder and service codes–typically each customer had several funder and service codes. The client now needed analyses of various combinations of those codes.
Given a well-designed data structure, developing the required reports should have been an easy task. The problem was that the initial developer had chosen to embed the service codes as concatenated strings in a memo field in the customer record (similarly, another memo field held concatenated funder codes). While the original design handled capturing the codes, it didn’t support working with them beyond simply reporting the collections of service and funder codes that applied to any particular customer.
The original developer failed to ask two simple questions. First, he or she should have asked the client, “How do you anticipate using these codes you’ve asked to be included in your database?” Second, the developer should have asked himself or herself, “Based on my experience and the experience of other developers, in what additional ways might the client use these codes?” The developer’s failure to recognize in his or her initial model that the funder and service codes were actually entities that deserved their own tables compounded the problem. Relegating them to concatenated memo fields made working with the codes far more complex and time-consuming than it should have been, given a properly devised data model.
However, analyzing the existing data further, I found that each table had compound, or multi-field, primary keys. Most often the component primary key fields were text fields. Maintaining the keys therefore required storing multiple fields in several tables. Further, because there can be up to three different funding sources for each service the client provides, each table requiring funder information had three groups of multiple funder fields.
The design shortcomings meant that the reporting solution my client needed was terribly costly and time-consuming to implement. The inflated cost was the direct result of a poorly modeled and ill-conceived database structure.
Defining relationships
Your design must not only include organizing data into an appropriate collection of tables; it must also include a detailed study of how each table relates to the other tables. Once again, knowledge and understanding of how the real-world entities relate to each other will guide you. The main objective here is to determine which of three possible types of relationships exists between each pair of tables. Is the relationship one-to-many, one-to-one, or many-to-many? (In this context, the word many merely means “more than one.”) Wherever you have a many-to-many relationship, you’re going to have to add another table to your database.
Once again, the methodology is straightforward. For each pair of tables, you need to write two simple statements that describe how each table relates to the other. For two tables, A and B, the first statement describes the relationship of table A to B; the second statement describes the relationship of table B to A.
You can then use the two statements to decide what type of relationship exists between the tables. Keep in mind that the tables are only models of real-world entities. The statements must correspond to the client’s stated or unstated real-world business rules and reflect the relationship between the real entities.
Here’s the technique applied to the five tables relevant to organizations, members, and categories discussed earlier.
Pair #1, organizations and members:
- Each organization can be represented by only one member.
- Each member can belong to many (more than one) organizations.
- Conclusion: There’s a one-member-to-many-organizations relationship.
These sentences reveal one of the failures of the original design. The original organization’s table design didn’t anticipate the one-to-many relationship between organizations and members. To accommodate this relationship, I added a new member field (a foreign key) to the Organization table to identify which member represents the organization (see Figure 1).
Figure 1 – Added member number
In different circumstances, the rules might be different. Membership might not be restricted, for example, to a single representative of each external organization. In that case the relationship would be many members to many organizations.
Pair #2, organizations and categories:
- Each organization can belong to many categories.
- Each category can include many organizations.
- Conclusion: The relationship between organizations and categories is many-to-many.
Because a relational database can’t directly represent a many-to-many relationship, such relationships require an additional table (a junction table) that has a one-to-many relationship with each partner of the many-to-many relationship. I called the junction table joining organizations and categories tjxOrganizationCategories. Each organization row can have many related records in the junction table, and each category row can have multiple records in the junction table. To implement this, the primary key of the organization and categories tables appears as a field in the tjxOrganizationCategories table.
Pair #3, members and categories:
- Each member can belong to more than one category.
- Each category can include more than one member.
- Conclusion: The relationship between members and categories is many-to-many.
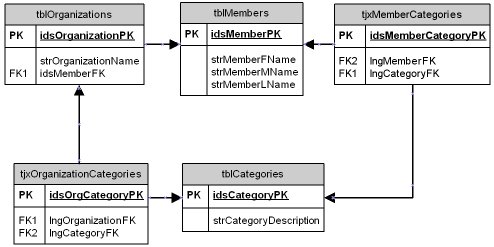
Once again, a table is required to join members to categories (tjxMemberCategories). The completed data model is shown in Figure 2.
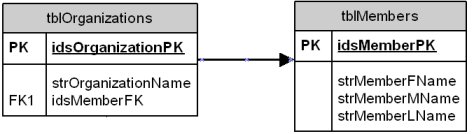
Figure 2 – The Completed Model
More than just a database solution
With a proper relational database structure in hand, the problem of dealing with membership in general and membership categories in particular becomes almost trivial. Where the initial solution had multiple records for some members, the new relational model will only ever have a single record for any given member. Changes to member information are centralized in a single record. The changes automatically propagate to any form, report, or query depending on the record.
Insightful data modeling is essential to good relational database design. At the very least, a poorly modeled database can damage an organization’s public image. At the very worst, bad modeling and design put the organization at risk of financial disaster. The three steps and two rules described in these two articles provide an approach to data modeling that any Access developer can implement. Successful data modeling does require an investment of time and effort. That investment is far outweighed by the very real costs of a poorly modeled database that constantly fails to meet its objectives.
