This month, Doug Steele looks at a common problem in database design: converting from one data classification schema to another. He then moves on to a related question: ensuring that there are no overlapping records in a list of ranges (for example, a list of scheduled events). This results in some thorny SQL, but the results can be used in a wide variety of circumstances.
I’ve got a database with student marks, and I want to convert the numeric marks to letter grades.
I’m going to start by looking at your specific problem, but by the end of the discussion you’ll see how this problem applies to other scenarios as well. For example, if you’ve got a table of date ranges, you may have occasion to assign a specific date to a particular group (for instance, does this date fall within our study period/sales period) or specify whether a particular value falls into a specific category (for example, does this tire’s pressure indicate that the tire is underinflated/overinflated/borderline/okay). Your question really reflects a universal problem: “How do I classify specific data values reliably and reduce a mass of data to key pieces of information?” Converting specific test marks into the categories defined by letter grades is a great example because there are so many categories–most of the times that you have to deal with this problem you’ll have only three or four categories.
The normal approach to classifying data is to create a second table that indicates the numeric range for each letter grade, and then join the two tables in some way. However, there are some potential gotchas with this approach, so I’ll go into more detail.
One of the first issues is how to actually construct the conversion table. It may seem obvious that you need to associate a minimum mark and a maximum mark with each letter grade. How should you do this, though? There seem to be two schools of thought on this. One has the minimum mark for one grade equal to the maximum mark for the previous grade, while the other school has the minimum mark for one grade just slightly higher than the maximum mark for the lower grade.
I don’t like the second approach, as it can lead to gaps in the calculation. If a B is 70-84 and an A is 85-100, what mark does someone with a score of 84.5 receive? I’m a believer in the first approach I mentioned, with attention paid to the inequalities used when joining the tables to ensure that no overlap occurs.
As an example, assume a table of marks like Figure 1, and a table of letter grade equivalents like Figure 2 (throughout this article I’ll use “mark” to refer to the unclassified numerical mark for the student, and “grade” to refer to the information organized into categories of the letter grade).
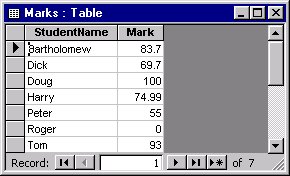
Figure 1
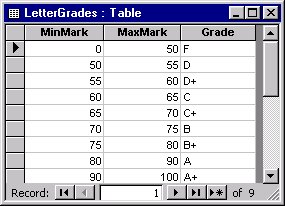
Figure 2
A common approach is to use a query like this:
SELECT M.StudentName, M.Mark, G.Grade FROM Marks AS M INNER JOIN LetterGrades AS G ON M.Mark BETWEEN G.MinMark AND G.MaxMark
The first problem you might encounter is that you can’t create queries like this in the Query Design view. You must go into the SQL view and type in the query. The real problem with this query, though, is that the Between operator is inclusive. Peter’s mark of 55 happens to be both a MaxMark in one row and a MinMark in another row, so his row will be joined to two different rows in the LetterGrades table, and he’ll show as having both a D and a D+ (see the upper left-hand chart in Figure 3).
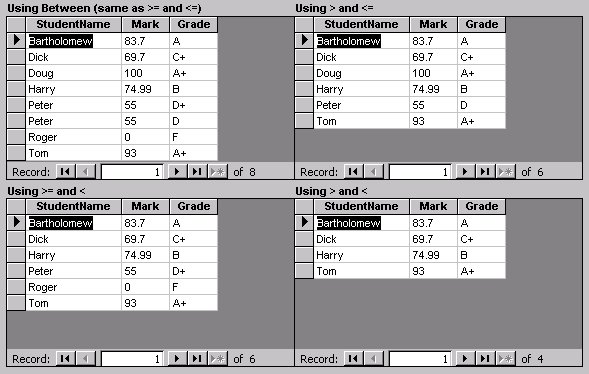
Figure 3
Unfortunately, simply changing the query to use more explicit inequalities doesn’t solve the problem. This query won’t work any better:
SELECT M.StudentName, M.Mark, G.Grade FROM Marks AS M INNER JOIN LetterGrades AS G ON M.Mark > G.MinMark AND M.Mark <= G.MaxMark
As the upper right-hand chart in Figure 3 shows, when I use “ON Mark > MinMark AND Mark <= MaxMark”, I miss assigning a grade for Roger, since his mark of 0 doesn’t match anything. Furthermore, Peter only gets a D for his 55, when I think he should get a D+.
The other two charts in Figure 3 show that further playing with the inequalities used doesn’t solve the problem either. When I use “ON Mark >= MinMark AND Mark <= MaxMark”, I miss assigning a grade for Doug, since his mark of 100 doesn’t match anything (although Peter now gets his well-deserved D+), whereas when I use “ON Mark > MinMark AND Mark < MaxMark”, three students (Roger, Peter, and Doug) don’t get a grade at all. The example “ON M.Mark >= G.MinMark AND M.Mark <= G.MaxMark” gives the same result as “ON M.Mark BETWEEN G.MinMark AND G.MaxMark”, so I’ve shown all four cases.
So what’s the answer? It turns out that I don’t really need to worry about MaxMark at all. I can determine which row in the LetterGrades table is closest to the mark (without exceeding it) using a comparison like this:
SELECT MAX(MinMark) FROM LetterGrades WHERE LetterGrades.MinMark <= Mark
This doesn’t give me the LetterGrade that’s in the same record as that mark, but I can get that by using a correlated subquery:
SELECT Grade FROM LetterGrades WHERE LetterGrades.MinMark = (SELECT MAX(MinMark) FROM LetterGrades WHERE LetterGrades.MinMark <= Mark)
This query isn’t complete yet, so don’t use it until you’ve read the next section. The query now returns the grade for the row that has the right mark. My original comparison query has now become a subquery that finds the right mark and returns that mark so that it can be used to find the right grade. I suspect that performance would be slow if the classification table were large. However, most classification tables are quite small (even my marks table has only about a dozen entries) and will process very quickly.
Since I also need to know the student name, I now create the following query that ties the query that selects the grades together with the list of students and their marks (I’ve numbered the lines for reference):
SELECT M.StudentName, M.Mark, (SELECT Grade FROM LetterGrades WHERE MinMark = (SELECT MAX(MinMark) FROM LetterGrades WHERE LetterGrades.MinMark <= M.Mark)) AS Grade FROM Marks AS M
While I apologize for the complexity of this query, it does return the correct values, as shown in Figure 4. My previous query now appears in lines 2-6, where it supplies the Grade field to what I’ll call the “main” query. The main query consist of lines 1, 2, and 7. Lines 1 and 2 select the student name, mark, and grade from the table called Marks (as specified in line 7). Of course, the Marks table doesn’t include the LetterGrade, so that field is retrieved using my previous query (the “inside” query).
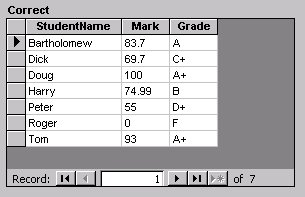
Figure 4
Also in line 7, I assign an alias (“M”) to the Marks table. As you can see, that alias is used in line 6 to specify where to get the Mark to be used in the inside query. As the main query processes the Marks table, as each Mark is retrieved, that Mark is fed to the inside query and used to control which row is selected from the LetterGrades table. The results of that query are used to select the row with the right grade, and that’s fed back to my main query.
Now that I’ve got a query to return the letter grades, how can I be sure that my LetterGrades table is correct?
Again, while I’ll start with your marking problem, I’ll finish by showing how to solve this problem more generally (you might need to check whether any dates in a table of date ranges overlap, for instance). As you saw, you don’t need the maximum mark at all to handle the classification problem. However, if you were maintaining a list of events that begin and end on specific dates, you’d want to make sure that no two events overlapped. Here, you do need both a minimum and a maximum date (probably called “StartDate” and “EndDate”). I’ll use the grade scenario to work through the problem and then switch to looking at dates.
First, I need to compare each row in the LetterGrades table to every other row in the LetterGrades table. The first step is relatively straightforward: Create a Cartesian product between two instances of the table (a Cartesian product is a query where every combination of the rows in the two tables is generated). I can do this by dragging the LetterGrades table into the Query Design grid twice. Access will rename the second instance to LetterGrades_1. For the sake of discussion, I’m going to rename both tables, to G1 and G2. Running this query creates a result consisting of every combination of the rows in G1 with the rows in G2.
Now I need to decide what constitutes a problem. While you could think in terms of “There’s a problem if MinMark in G1 is less than MinMark in G2, but only if MaxMark in G1 is greater than MinMark in G2” and so on, it turns out that it’s easier to think in terms of what’s not a problem than what is a problem: For every row in the table, MinMark has to be less than MaxMark. In that case, a given row from G1 doesn’t conflict with a given row from G2 if either of the following is true:
- The minimum mark for the row in G2 is greater than the maximum mark for the row in G1 (that is, G2 begins after G1).
- The maximum mark for the row in G2 is less than the minimum mark for the row in G1 (that is, G2 ends before G1).
Since I’m comparing rows in the same table with each other, I’ve joined every row to the copy of itself from the other instance of the table. So an additional test that I need to consider is when the row from G2 is the row in G1. As it turns out, that’s not a problem either. I can check all three conditions with this test (the last three lines check that the two rows are identical):
([G2].[MinMark]>=[G1].[MaxMark]) OR _ ([G2].[MaxMark]<=[G1].[MinMark]) OR _ ([G2].[MinMark]=[G1].[MinMark] AND _ [G2].[MaxMark]=[G1].[MaxMark] AND _ [G2].[Grade]=[G1].[Grade])
You could probably simplify this test by just checking that “G1.Grade = G2.Grade”, but that assumes that each row has some unique identifier that you could test this way.
Remember that the preceding expression will return True if there’s no conflict. Since I only want rows where there is a problem, my final test query looks something like this:
SELECT G1.Grade, G1.MinMark, G1.MaxMark, "Overlap" AS Comment FROM LetterGrades AS G1, LetterGrades AS G2 WHERE (([G2].[MinMark]>=[G1].[MaxMark]) OR ([G2].[MaxMark]<=[G1].[MinMark]) OR ([G2].[MinMark]=[G1].[MinMark] AND [G2].[MaxMark]=[G1].[MaxMark] AND [G2].[Grade] = [G1].[Grade])) = False ORDER BY G1.MinMark DESC;
Now, I’ll admit this isn’t the prettiest output, and I’m sure there’s probably a query that might present the information in a friendlier way. What this query returns is a list of rows that overlap, but it doesn’t actually highlight which row needs to be fixed.
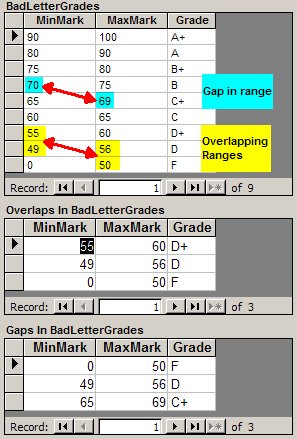
For example, assume that LetterGrades contains the data shown in the top of Figure 5. Here, you can see that the details for D aren’t correct: The minimum mark for a D is less than the maximum mark for an F, while the maximum mark for a D is greater than the minimum mark for a D+. Running the SQL shown earlier will return the results shown in the middle of Figure 5. Looking at the results, you still need to look closely to determine exactly what the problem is. However, my query does limit where you need to look–and lets you know that you do have a problem.
Figure 5
It’s also possible to expand on the techniques I showed in the Apr-2004 “Access Answers” column to check whether there are gaps in the ranges provided in the table. Earlier, I used this SQL:
SELECT MAX(MinMark) FROM LetterGrades WHERE LetterGrades.MinMark <= M.Mark
The SQL statements determine the value of MinMark in LetterGrades that’s closest to a given mark without exceeding it. Similarly, this SQL will give the value of MinMark in LetterGrades that’s closest to a given mark without being less than it:
SELECT MIN(MinMark) FROM LetterGrades WHERE LetterGrades.MinMark >= M.Mark
Since the value of MinMark should equal the value of MaxMark for the previous row, I should be able to use the preceding calculation to determine whether that’s the case using another correlated subquery:
SELECT G.MinMark, G.MaxMark, G.Grade FROM LetterGrades AS G WHERE G.MaxMark<> (SELECT MIN(MinMark) FROM LetterGrades WHERE MinMark >= G.MaxMark)
As you can see in the top of Figure 5, C+ goes from 65 to 69, and B goes from 70 to 75, so that’s a gap. Running the SQL will return the results shown in the bottom of Figure 5.
How can I extend this overlap-checking to clashing events or appointments?
A more common situation where you need to worry about checking for clashes is in scheduling applications. You might have a table along the lines of what’s shown in Table 1.
Table 1. Typical event table.
| Field name | DataType | Description |
| EventID | Autonumber | Primary key |
| EventName | Text | The name of the event |
| Start | Date/Time | Date/Time this event starts |
| End | Date/Time | Date/Time this event ends |
| LocnID | Number | FK, pointing to LocnId in the Location table |
Such a table could be used for meetings, sporting events, or classroom scheduling.
As before, it’s easier to think in terms of when an event doesn’t clash, rather than when it does. Two events don’t clash if any of the following is true:
- Event A starts after Event B ends.
- Event A ends before Event B starts.
- The locations for Event A and Event B are different.
- Event A is the same event as Event B.
Again, these four conditions can be checked with a test like the one that I used for grades:
([EventA].[Start]>=[EventB].[End]) OR _ ([EventA].[End]<=[EventB].[Start]) OR _ ([EventA].[LocnID]<>[EventB].[LocnID]) OR _ ([EventA].[EventID]=[EventB].[EventID]) Rewritten to handle events, my query will look something like this: SELECT EventA.EventID, EventA.Start, EventA.End, EventA.LocnID, EventB.EventID, EventB.Start, EventB.End, EventB.LocnID FROM Event AS EventA, Event AS EventB WHERE (([EventA].[Start]>=[EventB].[End]) OR ([EventA].[End]<=[EventB].[Start]) OR ([EventA].[LocnID]<>[EventB].[LocnID]) OR ([EventA].[EventID]=[EventB].[EventID])) = False
I want to go one step further this time, though. Assume that it’s possible an Event may have been added to the table without knowing the Start and/or the End and/or the Location. In this case, it’s not possible to know whether or not an event clashes with another event, so I’ll want to flag it as a possible problem that requires follow-up.
Now, the way the comparison operators work, if I compare two values and one of the values is Null, the result is Null. This means that if any of Start, End, or LocationID is Null, that specific comparison will result in Null. Fortunately, the OR operator cooperates with me: “Null = Null OR True” will return True, “False OR Null” will return Null. This means that my previous comparison will evaluate to:
- True if any of the four parts are True (regardless of whether any other parts are Null).
- False if all four parts are False.
- Null if any of the fours parts are Null, and no part is True.
What I want to do now is identify problems, which appear if the condition is False or Null. I could use this SQL:
SELECT EventA.EventID, EventA.Start, EventA.End, EventA.LocnID, EventB.EventID, EventB.Start, EventB.End, EventB.LocnID FROM Event AS EventA, Event AS EventB WHERE (([EventA].[Start]>=[EventB].[End]) OR ([EventA].[End]<=[EventB].[Start]) OR ([EventA].[LocnID]<>[EventB].[LocnID]) OR ([EventA].[EventID]=[EventB].[EventID])) = False OR (([EventA].[Start]>=[EventB].[End]) OR ([EventA].[End]<=[EventB].[Start]) OR ([EventA].[LocnID]<>[EventB].[LocnID]) OR ([EventA].[EventID]=[EventB].[EventID])) IS NULL
However, this involves doing all of the calculations twice. If the Event tables are large, this can lead to hundreds (or worse!) of unnecessary calculations. Since there’s no Join operator in my SQL statement, the resultant recordset is going to be a Cartesian product. If there are 500 records in table Event, the resultant Cartesian product will contain 25,000 rows. The computations will thus be done 50,000 times, even if there are no conflicts in the table. That’s 25,000 extra computations.
Rather than checking if the comparison is False or if it’s Null, I can use the Nz function to convert a Null value to False, so that the comparisons only need to be done once:
SELECT EventA.EventID, EventA.Start, EventA.End, EventA.LocnID, EventB.EventID, EventB.Start, EventB.End, EventB.LocnID FROM Event AS EventA, Event AS EventB WHERE Nz(([EventA].[Start]>=[EventB].[End]) OR ([EventA].[End]<=[EventB].[Start]) OR ([EventA].[LocnID]<>[EventB].[LocnID]) OR ([EventA].[EventID]=[EventB].[EventID]),False) = False
Other Pages That You Might Like To Read
Access Subquery Techniques
Combining Tables using Union Queries
Tame the Crosstab Missing Column Beast
Subquery Notes
You Can Do That with Datasheets?
Managing State Transitions
